Эффективное управление данными или аналитический модуль Case Studio

Сегодня практически все сферы бизнеса активно используют цифровые технологии в своей деятельности. Данные стали новым топливом для бизнеса, а потому процессы их извлечения, трансформации и загрузки приобретают особую, критическую важность.
В связи с этим требуются инструменты для эффективного управления большими потоками данных. В этой статье мы рассмотрим такие понятия как Big Data и ETL-системы, их суть и как они воплощены в аналитическом модуле Case Studio.
Что такое Big Data?
Под Big Data («большие данные») понимаются огромные объемы информации, которые не поддаются обработке с помощью обычных методов и требуют применения новых подходов.
Важной характеристикой Big Data является не только объем, но и разнообразие данных: это могут быть текстовые записи, изображения, видеофайлы, аудиозаписи и т.д. Источники информации тоже отличаются — от постов в социальных сетях и потоков с датчиков Интернета вещей (IoT) до транзакций в финансовой сфере.
Этот массив данных при правильном подходе способен стать мощным инструментом для создания конкурентного преимущества. На сегодняшний день компании используют большие данные для того, чтобы извлекать ценную информацию, прогнозировать рыночные тренды и эффективно управлять бизнесом. Возможность глубже понимать предпочтения клиентов, предсказывать изменения в поведении рынка и оптимизировать внутренние процессы — все это достигается с помощью инструментов Big Data.
Характеристики больших данных
Большие данные описываются не только своим масштабом, но и множеством других аспектов, которые определяют их уникальность и сложность в обработке. Основные характеристики Big Data можно свести к следующим признакам:
- Volume (Объем). Одной из ключевых черт Big Data является огромный объем информации, который исчисляется в терабайтах, петабайтах и даже эксабайтах. Современные компании генерируют и накапливают колоссальные массивы данных из множества источников, включая транзакции, пользовательские действия в Интернете, результаты научных исследований и многое другое.
- Variety (Разнообразие). Данные могут быть структурированными и неструктурированными, а также поступать в различных форматах — текст, изображения, видео, аудио, данные с географическими координатами, числовые данные.
- Velocity (Скорость). В мире больших данных скорость играет не меньшую роль, чем объем. Большие данные генерируются и поступают в режиме реального времени, иногда с частотой тысяч или даже миллионов транзакций в секунду. Это требует мгновенной реакции и инструментов, способных моментально обрабатывать информацию.
- Veracity (Истинность). Качество данных, их точность и достоверность — это неотъемлемая часть работы с Big Data. Большие объемы информации часто содержат шум или некорректные данные, и важно уметь отделять значимую информацию от ошибочной .
- Value (Ценность). Данные сами по себе не представляют ценности, если они не могут быть использованы для получения новых знаний и создания практических выводов. Способность извлекать из больших данных полезную информацию является основой работы с Big Data.

Что такое ETL?
Под термином ETL сегодня понимают процесс транспортировки и изменения данных, при котором информацию из разных мест преобразуют и кладут в новое место. ETL-процесс состоит из трех этапов:
- Извлечение (Extract).
На этом этапе происходит сбор данных из одного или нескольких источников. Список источников включает в себя базы данных, CRM-системы, файлы Excel и даже информацию, поступающую в режиме реального времени с веб-сервисов.
- Трансформация (Transform).
Извлеченные данные на первом этапе обрабатываются и преобразуются для удовлетворения аналитических потребностей. Процесс преобразования включает в себя очистку данных, агрегацию, масштабирование, конвертацию, и даже интеграцию с другими данными. Этот этап – подготовка к загрузке.
- Загрузка (Load).
Трансформированные данные загружаются в целевое хранилище, обычно это хранилище данных, где они становятся доступными для анализа и подготовки отчетности.
ETL-системы – мощный корпоративный инструмент. В отличие от стандартных инструментов управления базами данных или соответствующего программного обеспечения, ETL специализируется на объединении и трансформации данных из множества источников. Это делает такую систему идеальным вариантом для выполнения сложных задач интеграции.
Ключевые функции
Система ETL имеет широкий спектр возможностей, отличающих ее от более простых инструментов синхронизации или репликации данных. Ее ключевыми функциями являются:
- Поддержка сложных правил
ETL позволяет внедрять сложные правила в процесс трансформации данных, что критически важно для обеспечения точности и релевантности данных в хранилищах. Это отличает ETL от простых инструментов экспорта и импорта данных, которые не поддерживают сложные логические или математические операции. Вы получите итоговые сводки в простом и доступном виде.
- Масштабная автоматизация процессов
Такая функция дает возможность компаниям настраивать выполнение ETL-процессов на регулярной основе без необходимости ручного вмешательства. Это существенно упрощает поддержание актуальности данных в хранилищах и снижает вероятность возникновения ошибок.
- Расширение трансформации данных
Очистка, фильтрация, объединение, агрегация и другие виды преобразований станут намного проще и быстрее. Для работы с данными больше не будет необходимости держать целые отделы специалистов или оплачивать дорогостоящую аутсорс-аналитику – автоматическая аналитика позволяет значительно сократить затраты на привлечение кадров.
- Создание хранилищ данных для долгосрочного анализа
Эта функция отличает ETL от многих других систем управления данными, которые зачастую ориентированы строго на оперативную обработку текущих данных без сохранения и ведения истории изменений. Такое положение дел исключает ретроспективный анализ.
ETL – это бесконечно обширный спектр возможностей. Получить доступ к нему поможет качественная платформа с настраиваемыми модулями. Без функционала таких систем работа с большими данными становится трудоемкой и энергозатратной, а качество аналитики неизбежно падает.
Аналитический модуль от Case Studio
Аналитический модуль Case Platform или А-модуль — мощное решение для обработки больших данных, которое позволяет компаниям эффективно справляться с растущими объемами информации и оптимизировать процессы работы с данными. Эта система представляет собой конструктор ETL-процессов, построенный на принципах no-code и low-code.
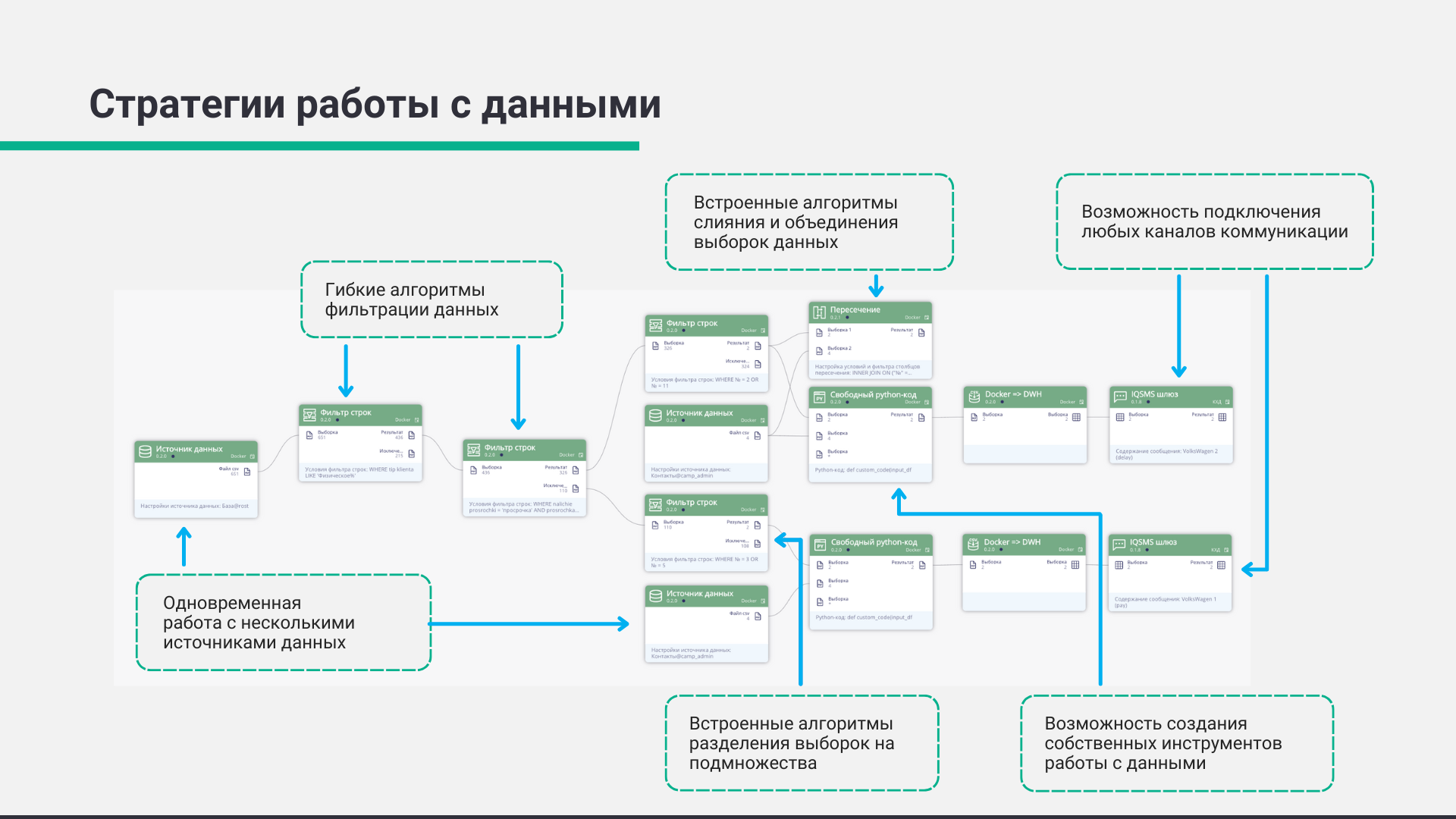
Благодаря гибкости и высокопроизводительным возможностям, платформа поддерживает все этапы обработки данных — от извлечения и трансформации до анализа и внедрения предиктивных моделей. Рассмотрим ключевые аспекты, которые делают Case Platform незаменимым инструментом для компаний, работающих с большими данными:
- No-code инструменты для создания сервисов. Быстрое создание сервисов без программирования позволяет компаниям разрабатывать решения для обработки больших данных, не привлекая разработчиков, существенно ускоряя их внедрение и адаптацию.
- Интеграция ETL-процессов на базе low-code технологий. Модуль упрощает создание процессов извлечения, трансформации и загрузки данных (ETL), позволяя пользователям легко настраивать пайплайны и адаптировать их под задачи по обработке больших данных.
- Эффективная очистка и фильтрация данных. Case Platform включает инструменты для очистки и фильтрации больших объемов данных, гарантируя высокое качество информации и позволяя создавать надежные пайплайны для последующей аналитики.
- Поддержка различных источников данных. Платформа обеспечивает простое подключение к широкому спектру источников больших данных, включая традиционные базы данных (PostgreSQL, Oracle), NoSQL-хранилища, а также распределенные файловые системы, такие как HDFS.
- Расширяемость и адаптация под большие данные с использованием кода. Несмотря на наличие no-code и low-code решений, Case Platform поддерживает написание собственного кода на языках программирования Java, Python и Scala, позволяя создавать кастомизированные решения для работы с большими данными.
- Параллельная и распределенная обработка данных. Модуль поддерживает как пакетную обработку данных (batch), так и обработку в режиме реального времени (online), что важно при работе с большими потоками информации. Платформа совместима и с DWH и Docker для удобного управления вычислительными ресурсами.
- Внедрение инструментов машинного обучения. Встроенные алгоритмы Machine Learning и искусственного интеллекта позволяют компаниям создавать предсказательные модели, которые могут анализировать большие объемы данных и принимать решения на их основе.
- Масштабируемость под большие данные. Case Platform гарантирует гибкое масштабирование системы — как вертикальное, так и горизонтальное. Это обеспечивает беспроблемную работу с увеличением объемов данных и нагрузок.
Практическое применения А-модуля
А-модуль включает в себя множество систем, которые позволяют сделать работу с большими данными проще и эффективнее. Один из способов практического применения приложения — это система Campaign Manager. Например, вам необходимо сегментировать базу данных для рекламной рассылки. Для этого вам нужно разбить базу на несколько групп по определенным параметрам, таким как возраст, пол, географическое положение, и сделать каждой группе отдельное уникальное предложение.
В таком случае А-модуль самостоятельно формирует SQL-запросы для манипулирования данными. Как только настройка выполнена, весь процесс можно поставить на автоматический режим, что позволяет исключить необходимость ручного вмешательства при последующих запусках.
Задачи оптимизации данных требуют более сложного подхода. Здесь используется система CPR. Для этого нужно не только сегментировать базу, но и подать каждый сегмент в расчетную модель. После важно принять решение о том, какой из вариантов является наиболее подходящим для дальнейшей работы. Если критерии для оценки результатов заранее определены, этот процесс можно также автоматизировать с помощью А-модуля. Такие системы, как правило, называются системами понятия решения. Они позволяют автоматически выбрать оптимальный вариант на основе заранее заданных правил, делая процесс принятия решений более быстрым и эффективным.
Для маркетологов А-модуль может стать незаменимым инструментом при реализации A/B тестирования. В этом случае используются Campaign Manager и CPR системы. Для A/B тестирования нужно не только сделать рассылку по базе данных, но и оценить ее результаты. Для этого в рамках одного сегмента данных создаются два подсегмента, которые впоследствии сравниваются между собой.
Все вышеперечисленное делает Case Platform незаменимым инструментом для обработки больших данных и ETL-систем , позволяя любому бизнесу извлекать максимальную пользу из информации, улучшать стратегическое планирование и повышать конкурентоспособность.
Бесплатная консультация специалиста
Наши менеджеры на связи и проконсультируют по всем вопросам.
ПОЛУЧИТЬ КОНСУЛЬТАЦИЮ